一文详解K8s的网络架构
技术选型
准备把之前用Docker搭建的服务往高可用集群上迁移,因为我的机器不是同一个厂商且网络架构各不相同,在集群组网方面踩了比较多的坑,写一篇博客记录一下.
机器选型
下面是我的集群配置,经典网络表示公网ip直接附加在虚拟机的网卡上,而VPC网络则附加的是内网IP
| 商家 | 角色 | 配置 | 网络类型 | 地理位置 |
|---|---|---|---|---|
| Servps | Master | 4C8G 60G SSD | 经典网络 | 香港 |
| HostHatch | Worker | 6C24G 275G SSD | 经典网络 | 香港 |
| Oracle | Worker | 4C24G 200G SSD | VPC网络 | 香港 |
平台选型
在前面的机器选型上我们的机器有两个缺点
- 机器配置低
- 机器不在同一个内网
因为配置低所以我们要选择平台占用不能高,且比较倾向于为边缘设备优化.
其次因为不同厂商的网络类型不同,不能直接建立连接,所以需要能够实现二层/三层组网(VPN)的容器编排平台.
最终我选择了K3s作为我最终的容器编排平台,当然原生K8s的安装我站内也有链接.
集群安装
前置准备
DD
如果可以的话最好直接把机器DD了,我把三台机器都DD成了Debian13,下面是DD的命令
wget https://raw.githubusercontent.com/bin456789/reinstall/main/reinstall.sh && bash reinstall.sh debian 13 --password <xxxxxxxxxxx>
修改主机名
因为DD完成之后机器的主机名都变成了localhost,可以用hostnamectl set-hostname命令修改成不一样的.
| 角色 | 主机名 |
|---|---|
| Master | BigMaster |
| x86 Worker | BigChicken |
| ARM Worker | BigArm |
一键安装
根据K3s的官方文档的快速入门可以获得K3s集群的一键安装命令.
因为需要进行二层/三层组网,所以在安装时指定了默认的flannel组件以wireguard-native模式运行,具体可以通过k3s文档的基础网络选项查看
# Master节点上运行
apt install wireguard -y && curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="server \
--node-name=xxxx \
--node-external-ip=xxx.xxx.xxx.xxx \
--flannel-external-ip \
--flannel-backend=wireguard-native \
--write-kubeconfig-mode 644 \
--disable=traefik" \
sh -
# Worker节点上运行
apt install wireguard -y && curl -sfL https://get.k3s.io | K3S_URL=https://<Master域名或者ip>:6443 \
K3S_TOKEN= <加入的token> \
INSTALL_K3S_EXEC="agent \
--node-name=xxxx \
--node-external-ip=xxx.xxx.xxx.xxx" \
sh -
请在安装时把
node-external-ip修改成该节点的公网IP
查看集群
接口/路由
首先查看一下每一台机器的接口以及路由,不难发现CNI插件将三个机器分了三个不同的网段
- Master: 10.42.0.0/24
- Arm Worker: 10.42.2.0/24
- X86 Worker: 10.42.3.0/24
创建pod时将会使用设置好的网段内的ip.
# -------------
# Master接口信息
# -------------
39: flannel-wg: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1420 qdisc noqueue state UNKNOWN group default
link/none
inet 10.42.0.0/32 scope global flannel-wg
40: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1420 qdisc noqueue state UP group default qlen 1000
link/ether 06:00:1f:1c:ca:a2 brd ff:ff:ff:ff:ff:ff
inet 10.42.0.1/24 brd 10.42.0.255 scope global cni0
# -------------
# Master路由信息
# -------------
default via xxx.xxx.xxx.1 dev ens3 onlink
10.42.0.0/24 dev cni0 proto kernel scope link src 10.42.0.1
10.42.0.0/16 dev flannel-wg scope link
xxx.xxx.xxx.0/24 dev ens3 proto kernel scope link src xxx.xxx.xxx.xxx
# -----------------
# X86 Worker接口信息
# -----------------
96: flannel-wg: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1420 qdisc noqueue state UNKNOWN group default
link/none
inet 10.42.3.0/32 scope global flannel-wg
97: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1420 qdisc noqueue state UP group default qlen 1000
link/ether 0e:27:4e:4d:f6:96 brd ff:ff:ff:ff:ff:ff
inet 10.42.3.1/24 brd 10.42.3.255 scope global cni0
# -----------------
# X86 Worker路由信息
# -----------------
default via xxx.xxx.xxx.1 dev ens3 onlink
10.42.0.0/16 dev flannel-wg scope link
10.42.3.0/24 dev cni0 proto kernel scope link src 10.42.3.1
xxx.xxx.xxx.0/24 dev ens3 proto kernel scope link src xxx.xxx.xxx.xxx
# -----------------
# ARM Worker接口信息
# -----------------
63: flannel-wg: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1420 qdisc noqueue state UNKNOWN group default
link/none
inet 10.42.2.0/32 scope global flannel-wg
64: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1420 qdisc noqueue state UP group default qlen 1000
link/ether e6:6b:de:e0:61:89 brd ff:ff:ff:ff:ff:ff
inet 10.42.2.1/24 brd 10.42.2.255 scope global cni0
# -----------------
# ARM Worker路由信息
# -----------------
default via 10.0.0.1 dev enp0s6 proto dhcp src 10.0.0.231 metric 1002 mtu 9000
10.0.0.0/24 dev enp0s6 proto dhcp scope link src 10.0.0.231 metric 1002 mtu 9000
10.42.0.0/16 dev flannel-wg scope link
10.42.2.0/24 dev cni0 proto kernel scope link src 10.42.2.1
169.254.0.0/16 dev enp0s6 proto dhcp scope link src 10.0.0.231 metric 1002 mtu 9000
集群状态
我们可以在Master节点上通过kubectl命令获取集群相关的状态
# 显示所有nodes
kubectl get nodes
NAME STATUS ROLES AGE VERSION
bigarm Ready worker 8d v1.33.6+k3s1
bigchicken Ready worker 8d v1.33.6+k3s1
bigmaster Ready control-plane,master 8d v1.33.6+k3s1
# 显示机器占用
kubectl top node
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
bigarm 903m 22% 5594Mi 23%
bigchicken 52m 0% 836Mi 3%
bigmaster 63m 1% 1237Mi 15%
# 显示所有Pod
kubectl get po -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-6d668d687-drnfm 1/1 Running 0 8d 10.42.0.4 bigmaster <none> <none>
kube-system local-path-provisioner-869c44bfbd-swq4z 1/1 Running 0 8d 10.42.0.2 bigmaster <none> <none>
kube-system metrics-server-8676bc86d-nssxm 1/1 Running 0 8d 10.42.0.3 bigmaster <none> <none>
# 显示所有
kubectl get all -A -o wide
集群已经安装完毕了!
节点间通信(L3)
先看一张架构图的展示吧,两台机器不属于同一个二层!
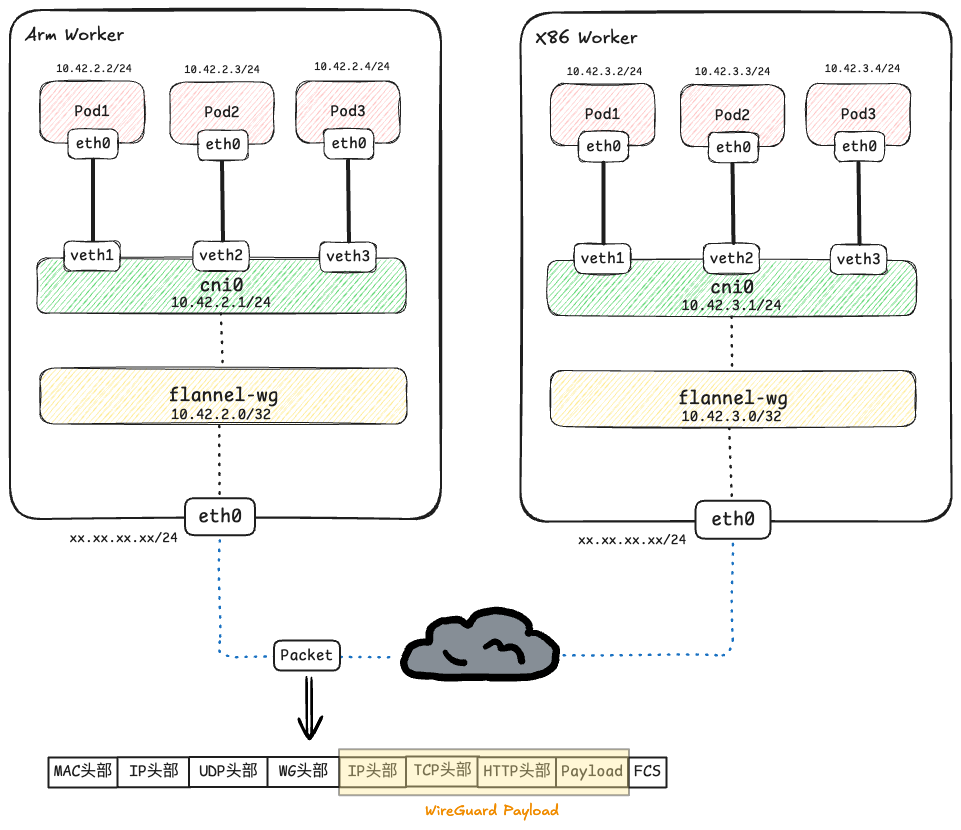
让我们以一个数据包为例:
一个位于ARM worker(10.42.2.0/24网段)上的Pod现在需要访问一个位于x86 worker(10.42.3.0/24网段)上的Pod.
假设:
- 源Pod(ARM Worker)的IP地址是
10.42.2.2 - 目标Pod(x86 Worker)的IP地址是
10.42.3.4
当源pod需要构建一个http请求发送到目标pod的80端口时
阶段一: 源Pod封装与ARM Worker路由决策
- 原始数据包构建(Pod1内部):
Pod1的应用程序生成HTTP请求数据- 传输层:
TCP头部(源端口:随机,目的端口: 80) - 网络层:
IP头部(源IP:10.42.2.2,目的IP:10.42.3.4)

-
流量进入ARM Worker:
Pod1生成的三层数据包通过veth对进入cni0网桥cni0网桥将流量转发给节点的内核协议栈.
-
内核路由查找及决策:
- 内核根据
目的IP(10.42.3.4)查找 ARM Worker 的路由表. - 路由表判断出最终走
10.42.0.0/16 dev flannel-wg这条路由,数据包从flannel-wg接口发出.
- 内核根据
阶段二: Flannel隧道封装(以 WireGuard 为例)
flannel-wg 接口是WireGuard隧道.数据包进入该接口后,被视为WireGuard的载荷(Payload).
- 隧道封装(L3 over UDP):
WireGuard将完整的原始IP包(阶段一的图片)作为L7层数据并进行加密,再次层层向下打包.- 传输层:
UDP头部(源端口:51820,目的端口:51820) - 网络层:
IP头部(源IP:ARM Worker的eth0 IP,目标IP:X86 Worker的eth0 IP)

- 跨网络传输:
- 封装后的
UDP数据包通过底层的L3路由(公网传输),从ARM Worker传输到x86 Worker.
- 封装后的
阶段三: X86 Worker接收和解封装
-
物理网卡
eth0接收:- 数据包到达
x86 Worker的物理网卡eth0. - 内核检查
目标IP是本机地址,于是接受该数据包. - 内核检查下一层协议是
UDP,并将数据包交付给UDP协议栈.
- 数据包到达
-
UDP端口查找与交付:
- 内核查看
UDP头部的目标端口是51820. - 内核知道端口51820被
flannel-wg接口(即WireGuard模块)监听和注册. - 内核将UDP包送到与该端口关联的
WireGuard模块进行处理.
- 内核查看
-
flannel-wg隧道处理与解封装:
WireGuard模块接收UDP负载.- 模块使用密钥进行解密,验证数据完整性,并剥离
UDP/WG外层头部. - 恢复出
原始IP数据包.
-
内核二次路由查找:
- 恢复后的
原始IP包被重新注入x86 Worker的协议栈,准备进行第二次路由决策. - 内核根据原始IP包的
目的IP(10.42.3.4)再次查找路由表,匹配10.42.3.0/24 dev cni0这条路由,数据包发送到cni0.
- 恢复后的
-
最终投递:
cni0网桥接收数据包,并转发到Pod3(10.42.3.4)的eth0接口,完成通信.
以上就是K3s Flannel CNI通过 WireGuard 三层进行通信的全过程!
Istio Ambient
我们已经了解了 K3s 集群通过 WireGuard 实现了底层的 L3 互通.现在我们将引入Istio Ambient Mesh来为我们的服务提供零信任安全和 L7 流量管理.
部署Ztunnel
Ambient Mesh 的核心优势在于它不需要传统的 Sidecar 容器,极大地减少了资源占用,这对于我们资源受限的集群环境非常理想.
可以通过查看官方文档获取安装方式,我这里选择通过helm包管理器安装.
安装前需要先安装helm二进制软件,并查看对应平台的安装注意事项!
#这里贴一下我的安装命令
# 建立一个 /etc/rancher/k3s/k3s.yaml 的软连接
ln -s /etc/rancher/k3s/k3s.yaml ~/.kube/config
# 添加helm的istio仓库
helm repo add istio https://istio-release.storage.googleapis.com/charts
# 更新
helm repo update
# 安装 K8s Gateway API CRD
# Kubernetes 社区的 稳定 标准 (稳定和实验标准二选一)
# 定义了gatewayclasses gateways httproutes grpcroutes referencegrants等模板
kubectl get crd gateways.gateway.networking.k8s.io &> /dev/null || \
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.4.0/standard-install.yaml
# 安装 K8s Gateway API CRD
# Kubernetes 社区的 实验 标准 (稳定和实验标准二选一)
# 定义了 包含稳定标准以及tlsroute tcproute udproute 等模板
kubectl kustomize "github.com/kubernetes-sigs/gateway-api/config/crd/experimental?ref=v1.4.0" | kubectl create -f -
# 安装 Istio 基础组件,其实也是添加CRD
helm install istio-base istio/base -n istio-system --create-namespace --wait
# 安装 Istiod 控制平面组件 Pod.
# 如果没有启用实验CRD可以删除env.PILOT_ENABLE_ALPHA_GATEWAY_API=true
helm install istiod istio/istiod --namespace istio-system \
--set profile=ambient \
--set "env.PILOT_ENABLE_ALPHA_GATEWAY_API=true" \
--set "affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].key=node-role.kubernetes.io/control-plane" \
--set "affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].operator=Exists" \
--wait
# 安装 CNI 插件,不安装在控制平面节点上,且设置平台为k3s,这个在注意事项里有写
helm install istio-cni istio/cni -n istio-system \
--set profile=ambient \
--set global.platform=k3s \
--set "affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].key=node-role.kubernetes.io/control-plane" \
--set "affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].operator=DoesNotExist" \
--wait
# 安装数据平面组件,不安装在控制平面节点上
helm install ztunnel istio/ztunnel -n istio-system \
--set "affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].key=node-role.kubernetes.io/control-plane" \
--set "affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].operator=DoesNotExist" \
--wait
# 在K3s中创建ServiceLB时如果不想被调度到master上需要创建标签
kubectl label node <节点hostname> svccontroller.k3s.cattle.io/enablelb=true
# 删除标签
kubectl label node <节点hostname> svccontroller.k3s.cattle.io/enablelb-
# 卸载命令也贴上吧
# 删除 ztunnel Chart
helm delete ztunnel -n istio-system
# 删除 istio-cni Chart
helm delete istio-cni -n istio-system
# 删除 istiod Chart
helm delete istiod -n istio-system
# 删除 istio-base Chart
helm delete istio-base -n istio-system
# 删除通过 Istio 安装的 CRD
kubectl get crd -oname | grep --color=never 'istio.io' | xargs kubectl delete
# 删除 istio-system 命名空间
kubectl delete namespace istio-system
# 删除 稳定 Kubernetes Gateway API CRD (稳定和实验二选一删除)
kubectl delete -f https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.4.0/standard-install.yaml
# 删除 实验 Kubernetes Gateway API CRD (稳定和实验二选一删除)
kubectl kustomize "github.com/kubernetes-sigs/gateway-api/config/crd/experimental?ref=v1.4.0" | kubectl delete -f -
这里还没有安装Waypoint Proxy(L7层代理),先说一下ztunnel如何先L4层代理.
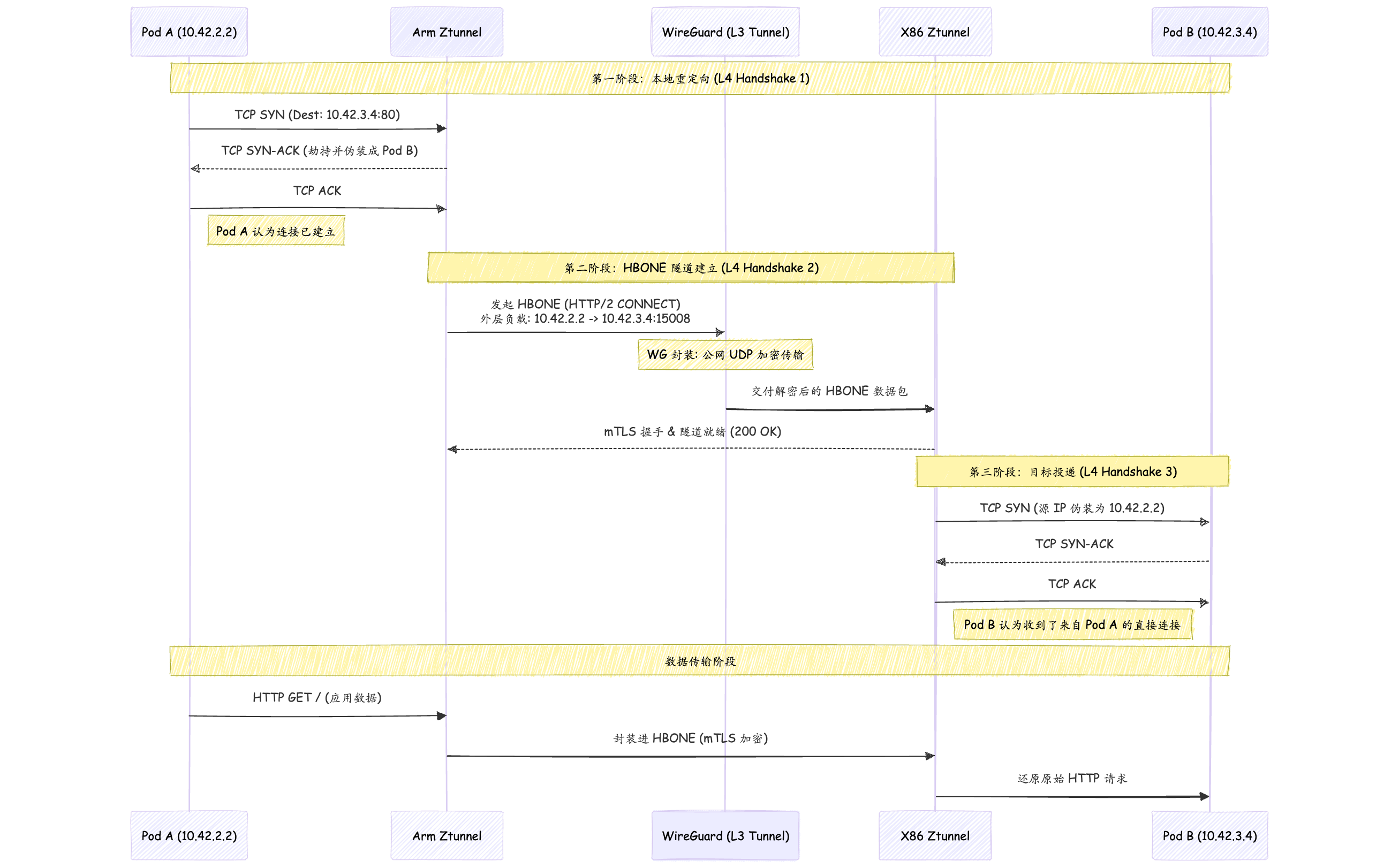
阶段一: ArmPod与本地Ztunnel的握手
架构流程图如下
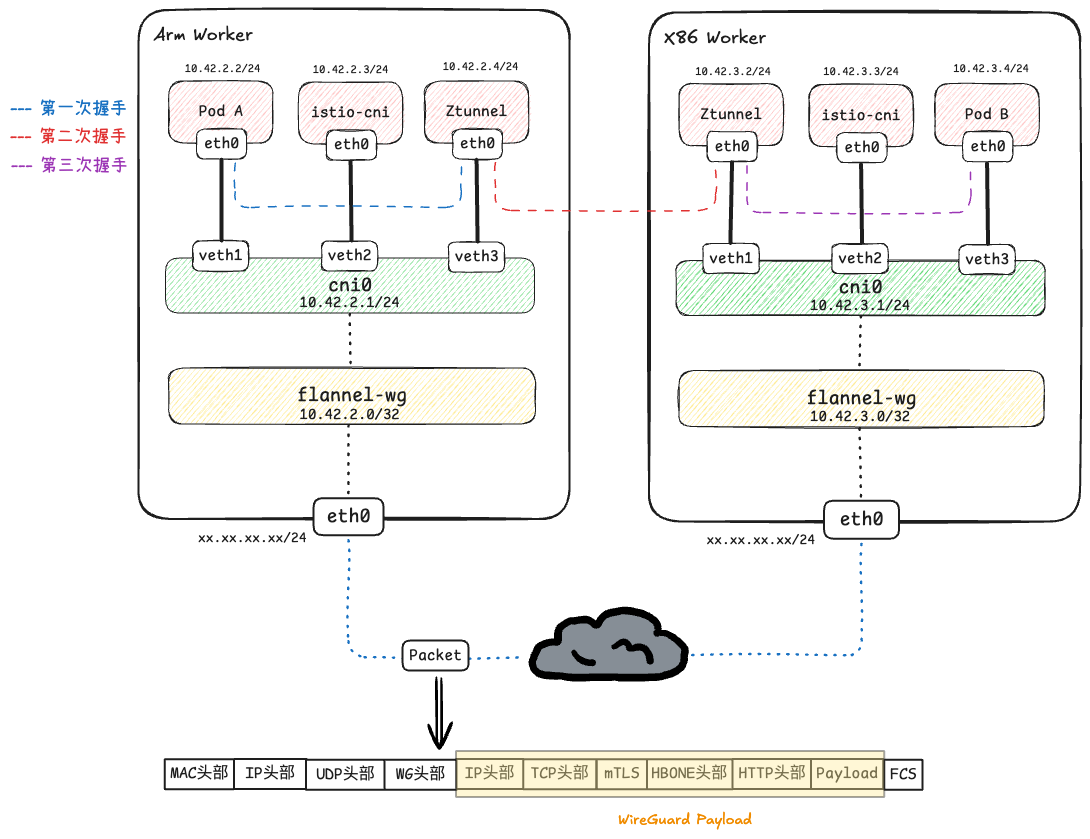
在每一个worker节点上,Istio Ambient模式会以DaemonSet形式创建istio-cni和Ztunnel这两个Pod.
Istio-cni负责监控节点上 Pod 的创建/销毁,并配置底层网络路由,将流量重定向到 ztunnel.Ztunnel作为节点级代理,负责处理 L4 层流量,提供 mTLS 加密、身份认证、L4 授权策略和遥测数据.
下面是L4层封装的通信过程
-
TCP SYN(Pod A -> Pod B):
- Arm Worker的
PodA(10.42.2.2:50000)发送TCP SYN给PodB(10.42.3.4:80). - 该包刚出PodA,就被Arm Worker上的eBPF程序拦截,直接重定向到本地的
Ztunnel Pod入站端口.
- Arm Worker的
-
SYN-ACK(Ztunnel -> Pod A):
- Ztunnel收到 SYN 后,假装自己是Pod B,向Pod A回复SYN-ACK.
-
ACK (Pod A -> Ztunnel):
- Pod A 回复 ACK.
- Pod A 侧的三次握手完成,连接已建立.Pod A开始发送应用数据如(如HTTP GET).
阶段二:Arm Ztunnel与X86 Ztunnel握手
当Arm Ztunnel收到Pod A的数据后,它发现目标是另一个Pod,于是它开始在两个节点间建立HBONE隧道.
-
建立外层TCP连接(Arm Ztunnel->X86 Ztunnel):
- Arm Ztunnel发起
HTTP/2 CONNECT请求,目标是目标节点X86 Ztunnel的监听端口(通常是15008). - TCP层: 源端口32451 -> 目标端口15008.
- IP层: 源IP10.42.2.2 -> 目的IP10.42.3.4.
- Arm Ztunnel发起
-
CNI 路由与 WG 封装:
- 内核查看目的IP 10.42.3.4,匹配路由表
10.42.0.0/16 dev flannel-wg. - WireGuard介入,将此包加密并封装发送到x86 Worker上.
- 内核查看目的IP 10.42.3.4,匹配路由表
-
接受数据包并解封装:
- WG解封装: X86的WireGuard模块解密包,暴露出: 10.42.2.2 -> 10.42.3.4:15008.
- 路由劫持: 看到目标端口是15008,立刻将包重定向给X86本地的ztunnel pod.
- 建立连接: Arm Ztunnel与X86 Ztunnel完成基于端口15008的 TCP 握手.
- mTLS握手: 在此15008连接内,两端 ztunnel 进行 TLS 握手.
阶段三: X86 Ztunnel与Pod B握手:
-
解析 CONNECT 指令:
- X86 Ztunnel 收到
HBONE请求后,解析出其中的CONNECT 10.42.3.4:80指令. - Pod B 收到 SYN,回复 SYN-ACK,连接最终建立.
- X86 Ztunnel 收到
-
本地TCP建立(Ztunnel->Pod B):
- X86 Ztunnel此时会发起一个新的本地 TCP 连接指向 Pod B。
- X86 Ztunnel利用底层路由能力,将这个
SYN包的源IP伪造为10.42.2.2(Pod A). - Pod B看到一个来自Pod A的连接请求,回复
SYN-ACK.
流程图如下